win32 汇编程序的结构
1 | ; ml /c /coff Test.asm |
模式定义
1 | .386 |
这些指令定义了程序使用的指令集、工作模式和格式。
指定使用的指令集
.386 语句是汇编语言的伪指令,类似的指令还有 .8086,.186,.386/.386p,.486/.486p 和 .586/.586p 等,用于告诉编译器使用的指令集。后面带 p 的伪指令表示程序中可以使用特权指令。
另外,intel公司的 80x86 系列处理器从 Pentium MMX 开始增加了 MMX 指令集,为了使用 MMX 指令,除了定义 .586 之外,还要加上一句 .MMX 伪指令。
1 | .586 |
.model 语句
.model 用来定义程序工作的模式,它的使用方法是:
1 | .model 内存模式[,语言模式][,其他模式] |
PS:中括号中的模式可写可不写
内存模式的定义影响最后生成的可执行文件,可执行文件的规模从小到大,可以有很多种类型。详见下表:
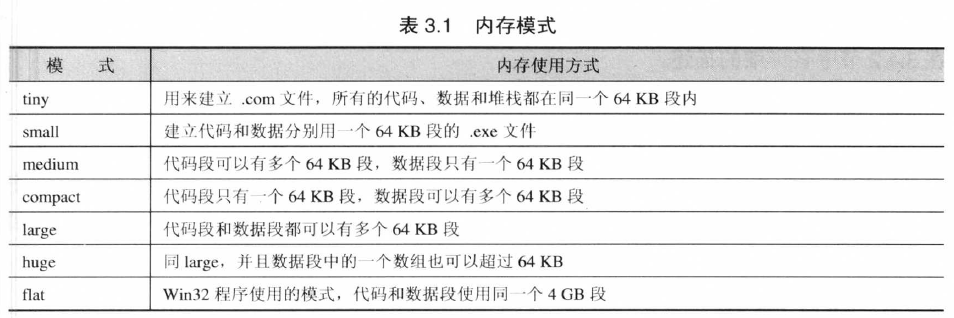
windows 程序运行在保护模式下,系统把每个 win32 应用程序都放到分开的虚拟地址空间中去运行,也就是说,每一个应用程序都拥有其相互独立的 4GB 地址空间。
在 win32 中只有一种内存模式 flat (平坦)模式,每个程序都可以使用自己独立的 4GB 地址空间,程序不再会有 64KB 段大小限制了。
纵观win32汇编的源程序,没有一处可以找到 ds 或 es等段寄存器的使用,因为所有的 4GB 空间用 32 位的寄存器全部都能访问,不必在头脑中随时记着当前是哪个数据段,这就是平坦内存模式带来的好处。
如果定义了 .model flat .MASM自动为各种段急促请你做了如下定义:
1
ASSUME cs:FLAT,ds:FLAT,ss:FLAT,es:FLAT,fs:ERROR,gs:ERROR
在 win32 汇编中,.model 语句中还应该指定语言模式,即子程序和调用方式,例子中用的是把 stdcall,它指出了调用子程序或win32 API时参数传递的次序和堆栈平衡的方法。相对于 stdcall,不同的语言类型还有 C,Syscall,BASIC ,FORTRAN 和 PASCALL,虽然各种高级语言在调用子程序时都是使用堆栈来传递参数,但是它们的处理方式各不相同。要和其他语言配合,就必须指定相应的语言种类。
各函数进堆栈的顺序:
1. C语言函数参数是按照倒序进栈,即函数调用时,最右边的参数最先压栈,由调用者恢复堆栈指针。
2. Pascall语言函数约定和C约定正好相反,它规定参数是从左向右传递,由被调用者恢复堆栈。
3. __stdcall 这是一种函数调用方式。 __stdcall方式函数的参数压栈顺序从右到左,是 Pascal 缺省调用方式,通常用于 win32 API中,自己在退出时清空栈。
4. __cdecl是C语言采用的默认调用方法,对于传送参数的内存栈却是由调用者来维护的。实现可变参数的调用只能用该方法。是MFC的缺省调用参数。
5. __fastcall方式的函数采用寄存器传递参数,VC将函数编译后会在函数名前面加上"@"前缀,在函数名后加上"@"和参数的字节数。
option 语句
option 语句定义的选项有很多,option casemap:none 这个语句定义了程序中的变量和子程序名是否对大小写敏感,由于 win32 API 中的 API 名称是区分大小写写的,所以必须指定这个选项,否则在调用 API 的时候会有问题。
段的定义
段的概念
.stack,.data,.data?,.code,.const 是分段伪指令,win32 中实际上只有代码和数据之分,.data,.data?和.const 都是数据段,.code 是代码段,与 DOS 汇编不同,由于 win32 汇编不必考虑堆栈,系统会为程序分配一个向下扩展的、足够大的段作为堆栈段,所以 .stack 段定义常常被忽略。这些 “段” 实际上并不是 DOS 汇编中那种意义上的段,而是内存的 “分段”。
数据段
.data,.data? 和 .const 定义的是数据段,分别对应不同方式的数据定义,在最后生成的可执行文件中也分别放在不同的节区(Section)中。 程序中的数据定义一般可以归纳为 3 类。
第一类是可读可写的已定义变量。这些数据在源程序中已经被定义了初始值,而且在程序的执行中有可能被更改,如一些标志等,这些数据必须定义在 .data 段中,.data 段是已初始化数据段,其中定义的数据是可读可写的,在程序装入完成的时候,这些值就已经在内存中了,.data 段一般存放在可执行文件的 _DATA 节区内。
第二类是可读可写的未定义变量。这些变量一般是当作缓冲区或者在程序执行后才开始使用的,这些数据可以定义在 .data 段中,也可以定义在 .data? 段中,但一般把它放到 .data? 段中。虽然定义在这两段中都可以正常使用,但定义在 .data? 段中不会增大 .exe 文件的大小。举例说明,如果要用到 100KB 的缓冲区,可以使用下面的语句定义:
1 | szBuffer db 100 * 1024 dup(?) |
这个语句如果放在 .data 段中,编译器认为这些数据在程序装入时就必须有效,所以它在生成可执行文件的时候保留了所有的 100 KB 的内容,即使它们全为零。.data? 段则不同,其中的内容编译器会认为程序在开始执行后才会用到,所以生成一个可执行文件的时候只保留了大小信息,不会为它浪费磁盘空间。.data? 段在可执行文件中一般存放在 _BSS 节区中。
第三类数据是一些常量。如果一些要显示的字符串信息,它们在程序装入的时候已经有效,但在整个执行过程中不需要修改,这些数据可以放在 .const 段中,.const 段是常量段,它是可读不可写的。为了方便起见,在小程序中常常把常量一起定义到 .data 段中,而不是另外定义一个 .const 段。在程序中如果不小心永乐对 .const 段中的数据做写操作的指令,会引起保护错误,如下图所示:

代码段
.code 是代码段,所有的是指令都必须卸载代码段中,在可执行文件中,代码段一般是放在 _YEXY 节区中的。win32 环境中的数据段是不可执行的,只有代码段有可执行的属性。对于工作在特权 3 的应用程序来说,.code 段是不可写的。代码段的属性是由可执行文件 PE 头部中的属性位决定的,通过编辑磁盘上的 .exe 文件,把代码段属性位改为可写,那么在程序中就允许修改自己的代码段。
堆栈段
在程序中不必定义堆栈段,系统会自动分配堆栈空间。堆栈段的内存属性是可读写并且是可执行的,这样靠动态修改代码段的反跟踪模块可以拷贝到中去边修改边执行。
程序入口
1 | end 标号 |
注释和换行
注释符号:“;”
换行符号:“\”
调用 API
API 是什么
Win32 程序是构筑在 win32 APi 基础上的。在 win32 API 中,包括了大量的函数、结构和消息等,它不仅为应用程序所代用,也是 windows 自身的一部分,windows 自身的运行也调用这些 API。API 就是将之前 DOS 的中断方式改为更简单的方法进行调用。与 DOS 的结构性相比,win32 的系统功能模块放在 windwos 的动态链接库(DLL)中,DLL是一种 windows 的可执行文件,采用的是和 .exe 文件额 PE 格式,在 PE 格式文件头的到处表中,已字符串的形式指出了这个 DLL 能提供的函数列表。应用程序使用字符串类型的函数名指定要调用的函数。
实际上 win32 的基础就是由 DLL 组成的。win32 API 的核心由 3 个 DLL 提供,分别是:
- KERNEL32.DLL——系统服务功能。包括内存管理、任务管理和动态连接等。
- GDI32.DLL——图形设备接口。利用 VGA 与 DRV 之类的显示设备驱动程序完成显示文本和矩形等功能。
- USER32.DLL——用户接口服务。建立窗口和传送消息等。
当然,win32 API 还包括其他很多函数,这些也是由 DLL 提供的,不同的DLL提供了不同的系统功能。
调用 API
与在 DOS 中用中断方式调用系统功能一样,用 API 方式调用存放在 DLL 中的函数必须同样约定一个规范,用来定义函数的调用方法、参数传递法和参数的定义。
win32 API 是用堆栈来传递参数的,调用者把参数一个个压入堆栈,DLL 中的函数程序再从堆栈中取出参数处理,并再返回之前将堆栈中已经无用的参数丢弃。先看下面 C 写的消息框函数的声明:
1 | int MessageBox( |
最后还有一句说明:
1 | Library: Use User32.lib |
上述函数声明说明了 MessageBox 有 4 个参数,他们分别是 HWND 类型的窗口句柄(hWnd),LPCTSTR 类型的要显示的字符串地址(lpText)和标题字符串地址(lpCaption),还有 NUIT 类型的消息框类型(uType)。所有这些 HWND、LPCTSTR 和 UINT 实际上就是汇编中的 dword。上面的声明用汇编的格式来表达就是:
1 | MessageBox Proto hWnd:dword,lpText:dword,lpCaption:dword,uType:dword |
最后一句 Library: Use User32.lib 则说明这个函数包含在 User32.dll 中。
win32 API 调用时要把参数放入堆栈,顺序是最后一个参数先进栈,在汇编中调用 MesageBox 函数的方法是:
1 | push uType |
在源程序编译链接成可执行程序后,call MessageBox 语句中的 MessageBox 会被换成一个地址,指向可执行文件的导入表,导入表指向 MessageBox 函数的实际地址会在程序装入内存的时候,根据 User32.dll 在内存中的位置由 windows 系统动态填入。
使用 invoke 语句
API 调用的时候还存在其他问题,win32 的 API 调用时动辄就是十几个参数,把这些参数压入栈中,参数的个数和顺序很容易搞错,导致程序在执行的时候报错。为了解决这个问题,MASM 提供了伪指令 invoke。使用格式如下:
1 | invoke 函数名[,参数1][,参数2]…… |
对于 MessageBox 的调用在 MASA 中可以写成:
1 | invoke MessageBox,NULL,offset szText,offset szCaption,MB_OK |
invoke 是伪指令,在编译的时候编译器把上面的指令展开成我们需要的 4 个 push 指令和 1 个 call 指令。同时进行参数数量的检查工作,如果带的参数数量和声明时的数量不符,编译器就会报错:error A2137: too few arguments to INVOKE。对于不带参数的 API 调用,invoke 伪指令的参数检查功能可有可无。
API 函数的返回值
有的 API 函数有返回值,返回值的类型对于汇编程序来说只有 dword 一种类型,它永远放在 eax 中。如果返回的内容不是一个 eax 所能容纳的,win32 API 采用的方法一般是 eax 中返回一个指向返回数据的指针,或者在调用参数中提供一个缓冲区地址,干脆直接换回到缓冲区中去。
函数的声明
在调用 API 函数的时候,函数原型也必须预先声明,否则,编译器会不认这个函数。invoke 伪指令也无法检查参数个数。声明函数格式如下:
1 | 函数名 proto [距离] [语言] [参数1]:数据类型,[参数2]:数据类型,…… |
proto 是函数声明的伪指令,距离可以是 NEAR,FAR,NEAR16,NEAR32,FAR16,FAR32,Win32 中只有一个段,无所谓距离,所以在定义时是忽略的。语言类型就是 .model 中的那些类型,如果忽略,则使用 .model 定义的默认值。
由于 win32 API 仅使用 dword 类型的参数,所以绝大多数的数据类型都是 dword,对于编译器来说,它也是只关心数量,参数的名称在这里没有用处,只是为了增减源码的可读性,所以参数是可以省略的。所以下面的消息框函数的定义实际上是一样的。
1 | MessageBox Proto hWnd:dword,lpText:dword,lpCaption:dword,uType:dword |
在 win32 环境中,和字符相关的 API 共有两类,分别对应两个字符集:一个是处理 ANSI 字符集的,另一个是处理 unicode 字符集的。处理 ANSI 的函数名字的尾部带一个 “A” 字符,处理 unicode 的则带一个 “W” 字符。
MessageBox 和显示字符串有关,所以有两个版本:
1 | MessageBoxA Proto hWnd:dword,lpText:dword,lpCaption:dword,uType:dword |
include 语句
对于所有要用到的 API 阿寒湖,在程序的开始部分都必须预先声明,这样太麻烦了。所以把所有的声明预先放在一个文件中,用到的时候在用 include 语句包含进来。现在这个 hello world 程序用到了两个 API 函数,MessageBox 和 ExitProcess,它们分别在 User32.dll 和 Kernal32.dll 中,在 MASM32 SDK 软件包中已经包括了所有 DLL 的 API 函数声明列表,每个 DLL 对应的 < DLL 名.inc > 文件,在源程序中只要使用 include 语句包含进来就行。
1 | include user32.inc |
当调用到其他的 API 函数时,只需要增加对应的 include 语句。include 语句还用来在源程序中包含其他文件。
include 语句的语法是:
1 | include 文件名 |
当遇到要包含的文件名和 MASM 的关键字同名时可能会引起编译器混淆的情况,这时可以用 “<>” 将文件括起来。
includelib 语句
在 win32 汇编中使用 API 函数,程序必须要知道调用的 API 函数在哪个 DLL 中,否则,操作系统必须搜索系统中存在的所有 DLL,冰球无法处理不同 DLL 中的同名函数,这显然不现实。所以 win32 就用导入库来定位 DLL 库的位置信息。
DOS 下的函数库的概念实际上就是静态库,静态库是一组已经编写好的代码模块,在程序中可以自由引用,在源程序编译成目标文件,最后要链接成可执行文件的时候,由 link 程序从库中找出相应的函数代码,一起链接到最后的可执行文件中。库的出现为程序员开发节省了很多时间,缺点是每个可执行文件中包含了要用到的相同函数的代码,占用了大量的磁盘空间,在执行程序的时候,这些代码同样重复占用了内存空间。
win32 环境中,程序链接的时候任然要使用函数库来定位函数信息,只不过由于函数代码放在 DLL 中,库文件中只保留函数的定位信息和参数数目等简单信息,这种库文件叫导入库,一个 DLL 对应一个倒入库,如 User32.dll 文件用于编程的导入库是 User32.lib,MASM32 SDK软件包含了所有 DLL 导入库。导入库的语法如下:
1 | includelib user32.lib |
和 include 语句处理不同,includelib 不会把 .lib 文件插入到程序中,它只是告诉链接器在链接的时候到指定的库文件中去找 API 函数的位置信息而已。
API 参数的等值定义
1 | invoke MessageBox,NULL,offset szText,offset szCaption,MB_OK |
在上面的消息框语句中 uType 参数使用了 MB_OK,这个表示消息框上显示按钮 “确定”。uType 参数是定义对话框的类型。这个蚕食可以是以下标志合集:
- 定义消息框显示按钮标志:
MB_ABORTRETRYIGNORE:消息框有三个按钮 “终止”,“重试” 和 “忽略”
MB_HELP:“帮助” 按钮,按下后发送 WM_HELP 消息
MB_OK:“确定” 按钮
MB_OKCANCEL:“确定” 和 “取消”
MB_RETRYCANCEL:“重试” 和 “忽略”
MB_YESNO:“是” 和 “否”
MB_YESNOCANCEL:“是”,“否” 和 “取消”
- 定义消息框显示的图标
MB_ICONWARNING:显示惊叹图标
MB_ICONINFORMATION:消息图标
MB_ICONASTERISK:危险图标
MB_ICONQUESTION:问号图标
MB_ICONSTOP:停止图标
……
这些只是 uType 参数说明中的一小半,可以使用 or 定义多个参数值,指令如下:
1 | invoke MessageBox,NULL,offset szText,offset szCaption,MB_ICONWARNING or MB_YESNO |
win32 汇编程序时,MASM32 SDK 软件包中的 windows.inc 包含了所有这些参数的定义,所以程序的开头要包含这个定义文件:
1 | include windows.inc |
标号、变量和数据结构
在 MASM 中标号和变量的命名规范是相同的:
- 可以使用字母、数字、下划线及符号 @、$ 和 ?
- 第一个符号不能是数字
- 长度不能超过 240 个字符
- 不能使用指令等关键字
- 在作用域内必须是唯一的
标号
标号定义格式:
1 | 标号名: 目的指令 ;方法1 |
标号在单个子程序中不能同名,否则编译器不知道要用哪个地址,但是不同的子程序中可以有相同的标号名称,这也就意味着不能在一个程序中使用跳转指令到另一个子程序中。
需要从一个子程序跳转到另一个子程序时,可以用方法2(两个冒号)来定义,这时的标号是作用在整个程序,其他任何子程序都能看见。
MASM 还可以使用 @@ 作为标号。当用 @@ 做标号时,可以用 @F 和 @B 来引用它,@F 表示本条指令后的第一个 @@ 标号,@B 表示本条指令前的第一个 @@ 标号,程序中可以使用多个 @@ 标号,但是 @B 和 @F 只能寻找匹配最近的一个。
全局变量
win32 汇编的全局变量定义在 .data 和 .data? 段内,可以同时定义边阿玲的类型和长度,格式是:
1 | 变量名 类型 初始值1,初始值2,…… |
MASM 中可以定义的变量:
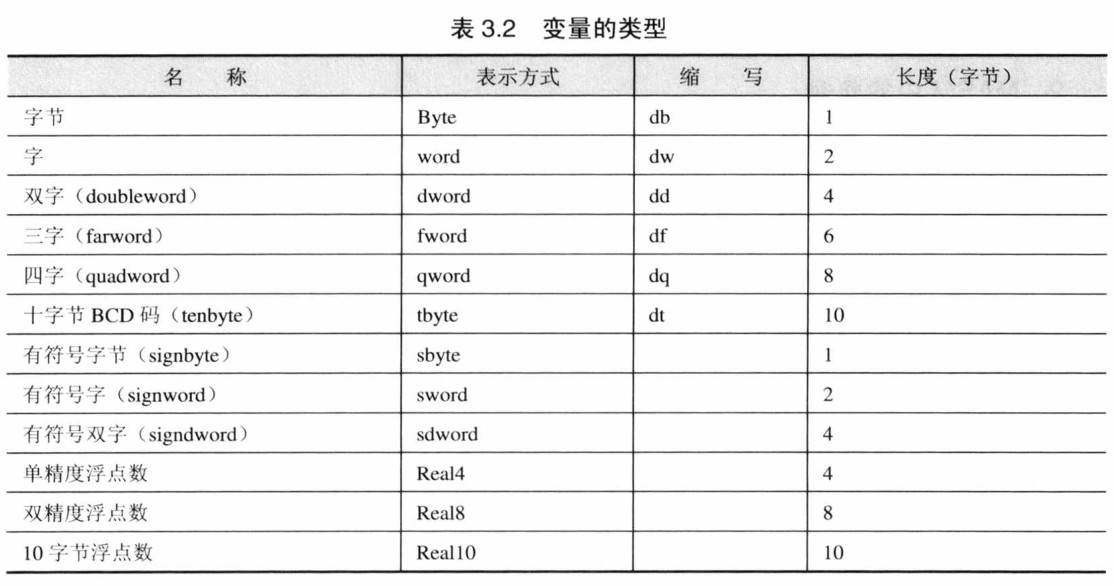
全局白能量定义示例:
1 | .data |
- 定义一个未初始化的 word 类型变量,名称为 wHour
- 定义一个名为 wMinute 的 word 类型变量,值为 10
- 定义一个双字型的变量_hWnd
- 定义一组字,以 0001,0002,0001,0002……的顺序在内存中重复 100 遍,一共是 200 个字
- 定义一个 1024 字节的缓冲区。
- 定义一个字符串,总共占用 12 字节。两头的单引号是定界的符号,并不属于真正的内容
在 byte 类型变量的定义中,可以用引号定义字符串和数值定义的方法混用,假设要定义两个字符串 “Hello,World!” 和 “Hello again”,每个字符串后面跟回车和换行符,最后以一个 0 字符结尾,可以定义如下:
1 | szText db 'Hello,world!',0dh,0ah,'Hello again',0dh,0ah,0 |
全局变量在定义中既可以指定初始值,也可以用问号预留空间,在 .data? 段中只能用问号预留空间,因为 .data? 不能指定初始值,这个未初始化的值为 0。
局部变量
局部变量定义格式:
1 | local 变量名1 [[重复数量]] [:类型],变量名2 [[重复数量]] [:类型],…… |
- local 伪指令必须紧接在子程序定义的伪指令 proc 后、其他指令开始前,这时因为局部变量的数目必须在子程序开始的时候确定下来。
- 语法中不能使用 dd、dw等类型的缩写,如果要定义数据结构可以使用数据结构的名称当做类型。win32 汇编中默认的类型是 dword,如果定义 dword 类型的局部变量,则类型可以省略。
- 当定义数组的时候可以使用 [] 括起来,不能使用定义全局变量 dup 伪指令。
- 局部变量不能和已定义的全局变量同名
- 局部变量的作用域是当前的子程序,所以在不同的子程序中可以有同名的局部变量
定义局部变量的例子:
1 | local locl [1024]:byte |
- 定义一个 1024 字节长的局部变量 loc1
- 定义一个名为 loc2 的局部变量,类型是默认值dword
- 定义一个 WNDCLASS 数据结构,名为 loc3
局部变量使用例子:
这是一个名为 TestProc 的子程序,用local 语句定义了3 个变量,@loc1 是 dword 类型,@loc2 是 word 类型,@loc3 是 byte 类型,在子程序中分别存取 3 个局部变量的指令,然后返回,编译成可执行文件后,再把它反汇编就得到了一下指令:


认真查看,反编译后真正执行的汇编指令有如下几条:
1 | mov eax, dword ptr [ebp-04] |
其余都多出来的指令:

执行 call 指令后,CPU 会把返回的地址压入栈(push esp),再转移到子程序(jmp 标号),esp 再程序执行过程中可能随时都能被用到,所以不能用esp 做指针来存取局部变量。ebp 寄存器也是以堆栈段为默认数据段,所以可以用 ebp 作为指针。
- 所以先用
push ebp指令把原来的 ebp 保存起来,然后再阿静esp 的值放到 ebp 中,供存取局部变量的指针用。 - 存数据到堆栈之前,要在堆栈中预留空间,由于堆栈是向下增长的,所以要在 esp 中加一个负值,FFFFFFF8 就是 -8 。理论来讲 dword + word + byte 一共是 7 个字节,但是因为 80386 处理器是以 dword 为界对齐时存取内存速度最快,所以 MASM 宁可浪费一个字节。执行了这 3 句指令后。局部变量在堆栈中的位置排列:
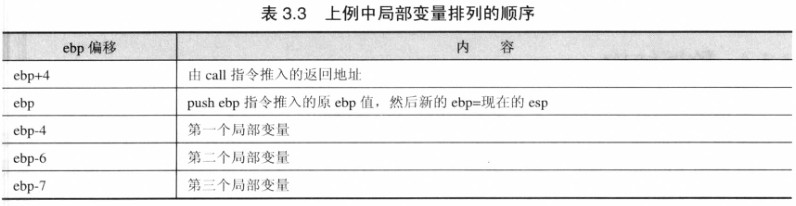
在 80386 指令集中一条指令可以依据实现 mov esp,ebp 和 pop ebp 的功能,就是 leave 指令,所以编译器在 ret 指令之前只是用了依据 leave 指令。
PS:call 指令占 4 个字节。
ebp 寄存器是关键,它起到保存原始 esp 的作用,并随时用做存取局部边阿玲的指针基地址,所以任何时刻,不要尝试把 ebp 用于别的用途,否则会带来意想不到的后果。
1 | 指针寄存器: |
局部变量和全局变量的初始值不同,局部变量的初始值是随机的,其他子程序执行后会在堆栈中残留,所以对局部变量的值一定要初始化。
数据结构
数据结构实际上是由多个字段组成的数据 “样板” ,相当于一种自定义的数据类型,数据结构中间的每一个字段可以是字节、字、双字、字符串或所有可能的数据类型。比如在 API 函数 RegistarC;ass 中要使用一个叫做 WNDCLASS 的数据结构,在汇编中的定义如下:

使用数据结构在数据段中定义数据的方法如下:
1 | .data? |
或者
1 | .data |
这个例子定义了一个以 WNDCLASS 为结构的变量 stWndClass,第一段的定义方法是未初始化的定义方法,第二段实在定义的同时指定结构中各字段的初始值,各字段的初始值用逗号隔开,在这个例子中 10 个字段的初始值指定为 1。
使用方法
- 举例使用 stWndClass 中的 lpfnWndProc 字段,最直接的方法是:
1 | mov eax,stWndClass.lpfnWndProc |
它表示把 lpfnWndProc 字段的值放入 eax 中去。假设 stWndClass 在内存中的地址是 403000h,这句话的指令会被编译成 mov eax,[4030004h],因为 lpfnWndProc 是 stWndClass 中的第二个字段,第一个字段是 dword,已经占用了 4 字节的空间。
- 实际常常有使用指针存取数据结构的情况,如果使用 esi 寄存器做指针寻址,可以使用下列的语句完成同样的功能:
1 | mov esi,offset stWndClass |
注意:第二句是 [esi + WNDCLASS.stWndProc] 而不是 [ eax,stWndClass.lpfnWndProc ],因为第一个会被编译成 mov eax,[esi+4],而后者会被编译成 mov eax,[esi+403004h],后者的结果显然是错误的。
- MASM 还可以用 assume 伪指令把寄存器预先定义为结构指针,再进行操作:
1 | mov esi,offset stWndClass |
这样使用寄存器也可以使用逗号引用字段名,程序的可读性比较好。这样的写法在最后编译成可执行程序的时候产生同样的代码。注意:在不使用 esi 寄存器做指针的时候要用 assume esi:nothing 取消定义。
- 结构的定义也可以是嵌套的,如果要定义一个新的 NEW_WNDCLASS 结构,里面包含了一个老的 WNDCLASS 结构和一个新的 dwOption 字段,那么可以如下定义:
1 | NEW_WNDCLASS struct |
假设现在 esi 是指向一个 NEW_WNDCLASS 的指针,那么引用里面嵌套的 oldWndClass 中的 stWndProc 时,就可以使用下面的语句:
1 | mvo eax,[esi].oldWndClass.stWndProc |
变量的使用
以不同的类型访问变量
MASM 中,如果要使用指定类型意外的长度访问变量,必须显示地指出要访问的长度,这样编译器忽略语法上的长度校验,仅使用变量的地址。使用方法是:
1 | 类型 ptr 变量名 |
类型可以是 byte,word,dword,fword,qword,real8 和 real10 如:
1 | mov ax,word ptr szBuffer |
需要注意的是,指定类型的参数访问并不会去检测字符的长度是否溢出,例如下面的例子:

各变量在内存中的存储布局
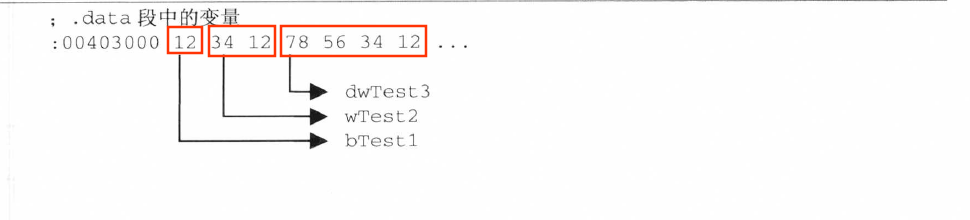
.data 段中变量是按顺序从低地址往高地址排列的,对于超过一个字节的数据,80386 处理器的数据排列方式是低数据在低地址。所以 mov al,bTest1 的 al=21h,mov ax,word ptr bTest1 的 ax=1234,mov eax,dword ptr bTest1 的 eax=12341278。
如果要使用类似于 C 语言的强制类型转换,想把 bTest1 的一个字节扩展到一个字或一个双字,高位保持 0 而不是越界存取到其他的变量,可以使用 80386 的扩展指令 movzx 来实现这个功能,该指令总是将扩展的数据位用 0 代替。
1 | movzx ax,bTest1 |
- 把单字节变量 bTest1 的值扩展到 16 位放入 ax 中
- 把单字节变量 bTest1 的值扩展到 32 位放入 eax 中
- 把 cl 中的 8 位扩展到 32 位放入 eax 中
- 把 ax 中的 16 位扩展到 32 位放入 eax 中
变量的尺寸和数量
在源程序中用到变量的尺寸和数量的时候,可以使用 sizeof 和 lengthof 伪指令来实现,格式是:
1 | sizeof 变量名、数据类型或数据结构名 |
sizeof 伪指令可以取得变量、数据类型或逐句结构以字节为单位的长度,lengthof 可以取得变量中的数据项数。假如定义以下数据

执行后 eax=40(stWndClass 结构的长度);ebx=40;ecx=13(“Hello,world!” + 一个字节的 0 结束符);edx=4(双字);esi=16(4个双字)
如果把所有的 sizeof 换成 lengthof,那么 eax=1(只定义了一项 WNDCLASS);ecx=13;esi=4;lengthof WNDCLASS 和 lengthof dword 是非法的,编译程序会报错。
sizeof 和 lengthof 的数值是编译时产生的,编译时会直接替换成如下代码:
1 | mov eax,40 |

获取变量地址
对于全局变量:
1 | mov 寄存器,offset 变量名 |
对于局部变量,它是用 ebp 来做指针操作的,由于 ebp 的值是随着程序的执行环境不同可能是不同的,所以局部变量的地址值是不确定的,不能用 offset 伪操作来获取它的地址。80386 中使用 lea 指令取得指针地址,如:
1 | lea eax,[ebp-4] |
该指令可以在运行时按照 ebp 的值实际计算出地址放在 eax 中。
如果要在 invoke 伪指令的参数中用到局部变量地址,此时可以用伪指令 addr,其格式如下:
1 | addr 局部变量名和全局变量名 |
当 addr 后跟全局变量名的时候,编译器会自动按照 offset 的方法来使用;当addr 互根局部变量名时候,编译器会自动用 lea 指令先把地址取到 eax 中。addr 是伪指令,不能用在 invoke 的参数中 和 mov 指令中。
使用子程序
当程序中相同的功能的一段代码用得比较频繁时,可以将它分离出来写成一个子程序,在主程序中用 call 指令调用它。win32 汇编中的子程序也是采用堆栈来传递参数,这样就可以用 invoke 伪指令来进行调用和语法检查工作。
子程序的定义
子程序的定义方式如下:
1 | 子程序名 proc [距离] [语言类型] [可视区] [USES 寄存器列表] [,参数:类型]...[VARARG] |
proc 和 endp 伪指令定义了子程序开始和结束的位置,proc 后面跟的参数是子程序的属性和输入参数。子程序的属性有:
距离——可以是 NEAR,FAR,NEAR16,NEAR32,FAR16,FAR32 通常忽略
语言类型——表示参数的使用方法和堆栈平衡方式,可使用 StdCall,C,SysCall,BASIC,FORTRAN 和 PASCAL,如果忽略,则使用程序头部 .model 定义的值。
可视区域——可以是 PRIVATE,PUBLIC 和 EXPORT。PRIVATE 表示子程序只对本模块可见;PUBLIC 表示对所有模块可见;EXPORT 表示是到处的函数,当编写 DLL 的时候要将某个函数导出的时候可以这样使用。默认设置是 PUBLIC。
USES 寄存器列表——表示由编译器在自陈谷指令开始前自动安排 push 这些寄存器的指令,并且在 ret 前自动 pop 指令,用于保存执行环境。
参数和类型——参数指参数的名称(不能和全局变量名和子程序局部变量名重名)。类型只有 dword 可忽略。在参数后面跟 VARARG,表示在已确定的参数后还可以跟多个不确定的参数。,在 win32 汇编中唯一使用 VARARG 的 API 就是 wsprintf,类似于 C 中的 printf。
完成定义后可以使用 invoke 调用子程序。当 invoke 语句在子程序前面时,需要先用 proto 伪指令定义子程序的信息,“提前” 告诉 invoke 语句关于子程序的信息。invoke 语句在子程序之后,proto 语句就可以省略。
参数传递和堆栈平衡
在调用子程序时,参数传递是通过堆栈进行的,也就说,调用者把要传递给子程序的参数压入堆栈,子程序在堆栈中取出相应的值再使用。如果要调用:
1 | SubRouting(Var1,Var2,Var3) |
经过编译后的最终代码可能是
1 | push Var3 |
也就说说,调用者首先把参数压入堆栈,然后调用子程序,在完成后,由于堆栈中先前压入的数不再有用,调用者或被调用者必须有一方把堆栈指针修正到调用前的状态,这就叫堆栈的平衡。参数入栈的顺序,还有修正堆栈的顺序都需要有个约定,不然会产生错误的结果。由于各种语言默认调用约定是不同的,所以在 proc 以及 proto 语句的语言属性中确定语言类型后,编译器才能将 invoke 伪指令翻译成正确的样子,不同语言的不同点如下表: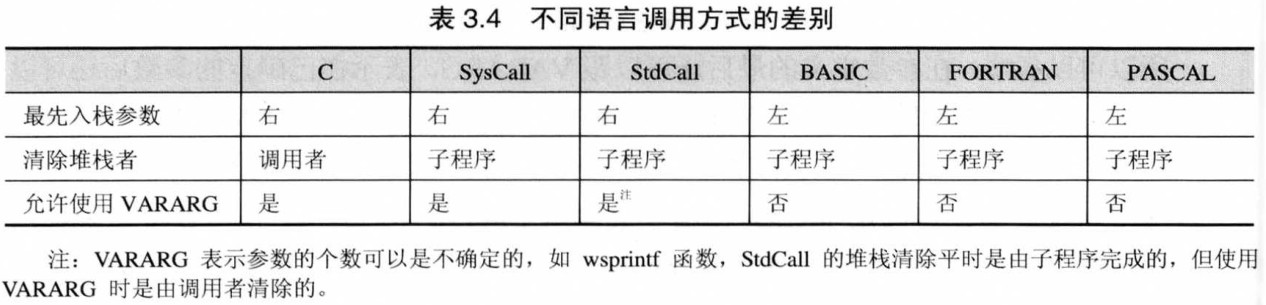
因为 win32 约定类型是 StdCall ,所以在程序中调用子程序或系统 API 后,不必自己来平衡堆栈,免去了很多的麻烦。
高级语法
以前高级语言和汇编的最大差别就是条件测试、分支和循环等高级语法。汇编只能在 cmp 指令后面绞尽脑汁考虑用哪个跳转语句,而且这些指令和寄存器纠缠在一起,使在汇编中书写结构清晰、可读性好的代码相当困难。
现在 MASM 中引用了一系列的伪指令,涉及条件测试、分支和循环语句,利用它们,汇编语言有了与高级语言一样的结构,配合对局部变量和调用参数等高级语言中常见元素的支持,为使用 win32 汇编编写大规模的应用程序奠定了基础。
条件测试语句
MASM 条件测试的基本表达式:
1 | 寄存器或变量 操作符 操作数 |
两个边大师可以用逻辑运算符连接:
1 | (表达式1)逻辑运算符(表达式2)逻辑运算符(表达式3)…… |
允许的操作符和逻辑运算符如下: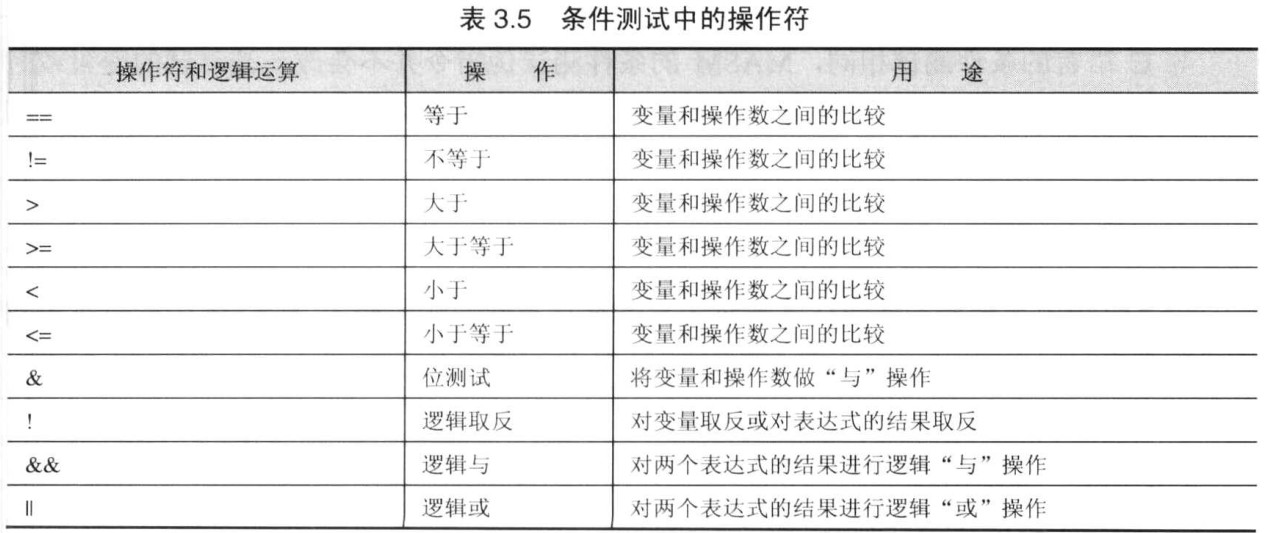
举例如下,左边为表达式,右边是表达式为 “真” 的条件:
1 | x==3 ;x等于3 |
MASM 的条件测试采用的是和 C 语言相同的语法。如 ! 和 & 是对变量的操作符(“取反”和“与”操作),|| 和 && 是表达式结果之间的逻辑“与” 和 逻辑“或”,而==、!=、>、<等是比较符。同样,对于不含比较符的单个变量或寄存器,MASM 也是讲所有非零值认为是“真”,零值认为是“假”。
MASM 的条件测试语句限制:
- 表达式的左边只能是变量或寄存器,不能是常数
- 表达式两边不能同时为变量,但可以同时是寄存器
- 不允许直接操作两个内存中的数
根据标志位进行条件跳转的表达式:
1 | CARRY? 表示 Carry 位是否置位 |
分支语句
MASM 中的分支语法如下:
1 | .if 条件表达式1 |
注意:关键字 if/elseif/else/endif 的前面有个小数点,如果不加小数点,就会变成宏汇编中的条件汇编伪操作。由 .if/.elseif/.else/.endif 条件分支伪指令构成的分支结构只能有一个条件被满足,也就说,程序按照从上到下的各个条件表达式,顺序判断,当第一个条件表达式满足的时候,执行相应的代码,然后就忽略掉下面所有的其他条件表达式,即使后面有另一个满足条件时也是如此。
如果需要构成分支对所有的表达式为“真”都要执行相应的代码,可以利用多个 .if/.endif 来完成,如下所示:
1 | .if 表达式1 |
循环语句
循环的语法:
1 | .while 条件测试表达式 |
或
1 | .repeat |
.while/.endw 循环首先判断条件测试表达式,如果结果是“真”,则实行循环体内的指令,结束后再回到 .while 处判断表达式,如果结果表达式是为“假”就会跳出循环。
.repeat/.until 循环首先执行一遍循环体内的指令,然后再判断条件测试表达式,如果结果为“真”的话,就退出循环,如果是“假”,则返回 .repeat 处继续循环
代码风格
变量和子程序的命名:类型前缀+变量说明,乐行用小写字母表示,变量说明首字母大写。汇编中常见的类型前缀有: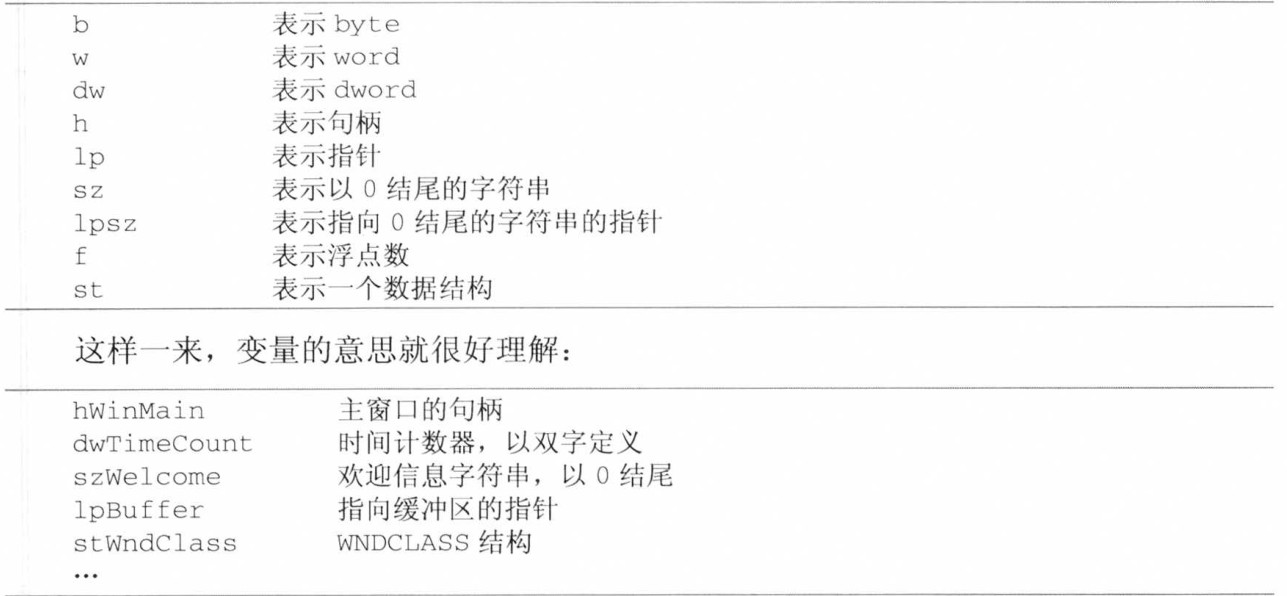
- 全局变量使用标准的匈牙利表示法,在参数的前面加下划线,局部变量前加@符号
- 内部子程序前加下划线,以便和系统API区别
大小写
所有的指令和寄存器都用小写,用equ伪操作符定义的常量使用大写,变量和标号使用大小写混合。
缩进
一般变量和标号定义不缩进,指令用两个 tab 缩进,遇到分支和循环伪指令再缩进一格。
注释和空行
- 不要写无意义的注释
- 修改代码的同时也要修改注释
- 注释以描写一组指令实现的功能为主,不要解释单个指令的用法。
- 对于子程序,要在头部加注释说明参数和返回值,子程序可以实现的功能,以及调用时应该注意的事项。
- 本文标题:80386汇编-使用MASM
- 本文作者:9unk
- 创建时间:2020-10-15 23:24:32
- 本文链接:https://9unkk.github.io/2020/10/15/80386-hui-bian-shi-yong-masm/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!