OSI参考模型、TCP/IP 参考模型

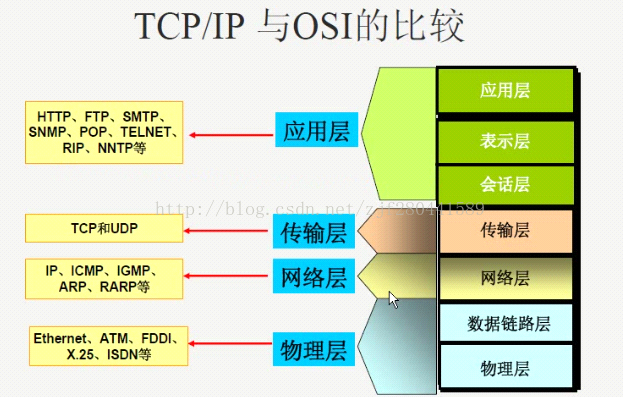
国际标准化组织(ISO)和国际电报电话咨询委员会(CCITT)联合开发了这个七层的参考模型,目的就是规范不同网络设备厂家使用相同通信协议,让不同的网络设备互联起来。但是 OSI 模型仅仅停留在理论概念,没有开发出符合 OSI 模型的具体协议实现,推广力度也没有后来的 TCP/IP 大。所以最后只剩下 OSI 参考模型,而我们在现实中用的基本都是 TCP/IP 模型和协议族。
TCP/IP 通信传输过程(以HTTP协议为例)
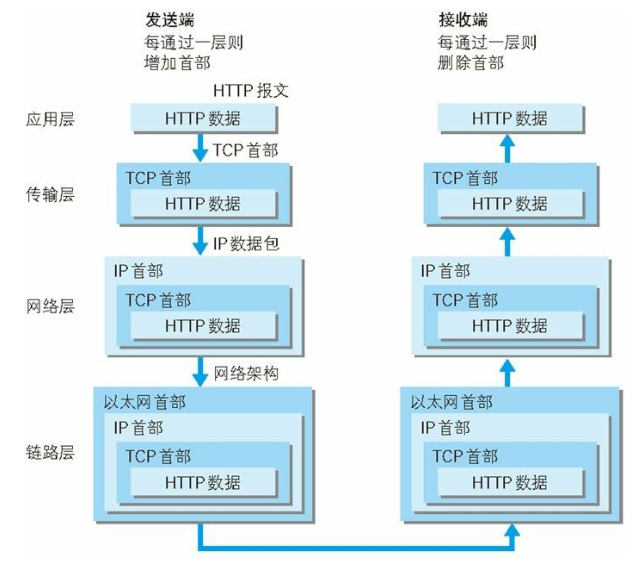
首先作为发送端的客户端在应用层(HTTP 协议)发出一个想看某个 Web 页面的 HTTP 请求。
接着,为了传输方便,在传输层(TCP 协议)把从应用层处收到的数据(HTTP 请求报文)进行分割,并在各个报文上打上标记序号及端口号后转发给网络层。
在网络层(IP 协议),增加作为通信目的地的 MAC 地址后转发给链路层。这样一来,发往网络的通信请求就准备齐全了。
接收端的服务器在链路层接收到数据,按序往上层发送,一直到应用层。当传输到应用层,才能算真正接收到由客户端发送过来的 HTTP请求。
HTTP 工作过程
HTTP工作过程简单概括就是四个步骤
客户端和服务端建立TCP连接
客户端向服务端发送请求
HTTP服务器向客户端返回状态和内容
客户端接收完成后,向服务器发送请求,服务端关闭 TCP/IP 连接
HTTP 详细的工作过程
这里以谷歌浏览器,访问博客为例(https://www.uiihh.xyz/)
在建立连接之前,浏览器会先解析 DNS,获取服务器 IP 地址,然后再建立 TCP 连接。
Chrome搜索自身的DNS缓存,看有没有对应该域名的IP地址,这个缓存的时间只有一分钟。
(查看浏览器自身缓存:chrome://net-internals/#dns)
如果在浏览器没有找到缓存或者缓存已经失效,则搜索操作系统自身的 DNS 缓存。
如果在操作系统中也没有找到缓存或者缓存已经失效。则读取本地的host文件。
(host文件:window在System32\drivers\etc;mac在finder中按快捷键组合 Shift+Command+G 三个组合按键,并输入 Hosts 文件的所在路径:/etc/hosts)
如果在host文件中找不到对应的配置,浏览器则发起一个DNS的系统调用。
主机向本地域名服务器(宽带运营商服务器)发出查询(主机向本地域名服务器的查询一般是递归查询)。
本地域名服务器查看本身缓存。
如果本地域名服务器没有该域名的缓存,则发起一个迭代 DNS 解析的请求。
本地域名服务器会向根域名服务器发送迭代查询请求报文,查询域名对应的 IP 地址。如果根域名服务器知道,则给出IP地址;否则,根域名服务器会给出 com 域的顶级域名服务器的 IP 地址,让本地域名服务器再向顶级域名服务器查询。
本地域名服务器向顶级域名服务器发送迭代查询请求报文,查询域名对应的IP地址。如果顶级域名服务器知道,则给出 IP 地址;否则,顶级域名服务器会给出 uiihh.xyz 域的权限域名服务器的 IP 地址,让本地域名服务器再向权限域名服务器查询。
到了 uiihh.xyz 域的权限域名服务器(域名注册商的地址,例如万网),拿到www.uiihh.xyz 对应的IP地址。
本地域名服务器把结果返回操作系统内核同时缓存起来。
操作系统内核把结果返回浏览器。
最后浏览器拿到了 uiihh.xyz 对应的 IP 地址。
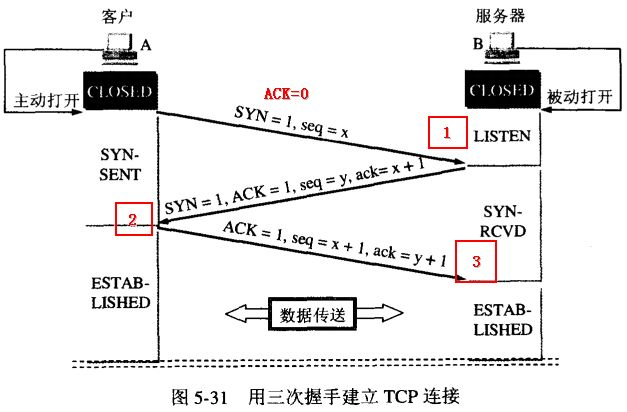
第一次:A 随机选取一个序列号 x,并发送给 B,说“我想和你建立连接”。
第二次:B 接收到数据,使用 确认序号ACK 进行确认,并发送数据给 A,说“我已经接收到你的请求,你现在可以连接了。”
第三次:A 收到服务器端的确认后,然后向 B 发送确认信息说 “我已经建立好连接了,你确认一下”。这时,TCP 连接以建立,A 进入 ESTABLISHED(已建立连接)状态。
第四次:B 收到 A 的确认消息后,B 进入 ESTABLISHED(已建立连接)状态
A 最后再次向 B 发送确认信息主要是为了预防下面的情况:
A 发送请求给 B,但是发送地时候数据包而被滞留在某个节点,对于 A 来说这个请求已经失效了,它已经不连这个通道了。但是又过了一会请求传到了 B,B 看到了认为是 A 刚发送过来的,所以 B 建立连接。最后造成 B 的资源浪费。
一旦建立了TCP连接,客户端就会向服务器发送请求命令
例如:GET/sample/hello.jsp HTTP/1.1
客户端发送其请求命令之后,还要以头信息的形式向服务器发送一些别的信息,之后客户端发送了一空白行来通知服务器,它已经结束了该头信息的发送
客户端向服务器发出请求后,服务器会客户端返回响应;
例如: HTTP/1.1 200 OK
响应的第一部分是协议的版本号和响应状态码
正如客户端会随同请求发送关于自身的信息一样,服务器也会随同响应向用户发送关于它自己的数据及被请求的文档
服务器向客户端发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以 Content-Type 响应头信息所描述的格式发送用户所请求的实际数据
一般情况下,一旦服务器向客户端返回了请求数据,它就要关闭 TCP 连接,然后如果客户端或者服务器在其头信息加入了这行代码 Connection:keep-alive ,TCP 连接在发送后将仍然保持打开状态,于是,客户端可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
HTTP1.1 协议的特性
1.1 版的最大变化,就是引入了持久连接(persistent connection),即 TCP 连接默认不关闭,可以被多个请求复用。
客户端和服务器发现对方一段时间没有活动,就可以主动关闭连接。不过,规范的做法是,客户端在最后一个请求时,发送 Connection: close,明确要求服务器关闭 TCP 连接。(就是用户浏览器的整个网页加载完成后,会发送 Connection: close 给服务器,告诉它网页已经加载好了,你可以关闭服务器了)。目前,对于同一个域名,大多数浏览器允许同时建立 6 个持久连接。
1.1 版还引入了管道机制(pipelining),即在同一个TCP连接里面,客户端可以同时发送多个请求。这样就进一步改进了HTTP协议的效率。
举例来说,客户端需要请求两个资源,分别是 A 和 B。管道机制则是允许浏览器同时发出 A请求 和 B请求,但是服务器还是按照顺序,先回应A请求,完成后再回应 B请求。
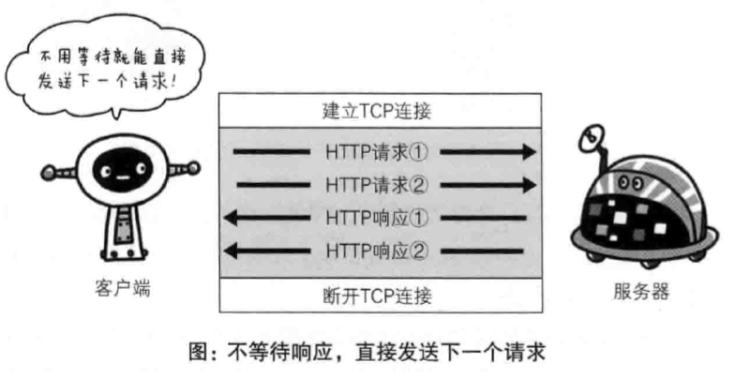
管道连接和非管道连接的区别
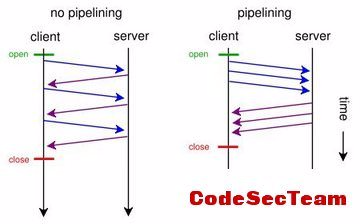
一个TCP连接现在可以传送多个回应,势必就要有一种机制,区分数据包是属于哪一个回应的。这就是Content-length字段的作用,声明本次回应的数据长度。
Content-Length: 3495
上面代码告诉浏览器,本次回应的长度是3495个字节,后面的字节就属于下一个回应了。
在1.0版中,Content-Length字段不是必需的,因为浏览器发现服务器关闭了TCP连接,就表明收到的数据包已经全了。
使用 Content-Length 字段的前提条件是,服务器发送回应之前,必须知道回应的数据长度。
对于一些很耗时的动态操作来说,这意味着,服务器要等到所有操作完成,才能发送数据,显然这样的效率不高。更好的处理方法是,产生一块数据,就发送这块数据,不要等待整串数据生成完成后再发送。也就是用”流模式”(stream)取代”缓存模式”(buffer)。
因此,1.1版规定可以不使用Content-Length字段,而使用”分块传输编码”(chunked transfer encoding)。只要请求或回应的头信息有Transfer-Encoding字段,就表明回应将由数量未定的数据块组成。
字段如下所示:
1 | Transfer-Encoding: chunked |
每个非空的数据块之前,会有一个 16 进制的数值,表示这个块的长度。最后是一个大小为0的块,就表示本次回应的数据发送完了。下面是一个例子。
1 | HTTP/1.1 200 OK |
1.1版还新增了许多动词方法:PUT、PATCH、HEAD、 OPTIONS、DELETE。另外,客户端请求的头信息新增了Host字段,用来指定服务器的域名。
1 | Host: www.example.com |
有了Host字段,就可以将请求发往同一台服务器上的不同网站,为虚拟主机的兴起打下了基础。
主要还是因为管道机制(pipelining)
客户端发送 ”请求1“ 时,不需要等待服务端响应了就可以发送 “请求2” 了,但是服务端只有处理完 “请求1” 后才会处理 “请求2”,所以客户端还是需要按照响应的顺序来接收。如果第一个响应很慢,后面就会有很多的请求派对等着,这时就会出现阻塞的情况。专业名称叫做 “线头阻塞” (Head of line blocking)简称:HOLB。
为了避免这个问题,只有两种方法:一是减少请求数,二是同时多开持久连接。这导致了很多的网页优化技巧,比如合并脚本和样式表、将图片嵌入CSS代码、域名分片(domain sharding)等等。如果HTTP协议设计得更好一些,这些额外的工作是可以避免的。
所以,这个 pipelining 仅仅是限于理论场景下,大部分桌面浏览器仍然会选择默认关闭 HTTP pipelining
HTTP 请求

由上图可以看到,http请求由请求行,消息报头,请求正文三部分构成。
HTTP请求状态行
请求行由请求Method, URL 字段和HTTP Version三部分构成, 总的来说请求行就是定义了本次请求的请求方式, 请求的地址, 以及所遵循的HTTP协议版本例如:
1 | GET /example.html HTTP/1.1 (CRLF) |
HTTP协议的方法有:
- GET: 请求获取Request-URI所标识的资源
- POST: 在Request-URI所标识的资源后增加新的数据
- HEAD: 请求获取由Request-URI所标识的资源的响应消息报头
- PUT: 请求服务器存储或修改一个资源,并用Request-URI作为其标识
- DELETE: 请求服务器删除Request-URI所标识的资源
- TRACE: 请求服务器回送收到的请求信息,主要用于测试或诊断
- CONNECT: 保留将来使用
- OPTIONS: 请求查询服务器的性能,或者查询与资源相关的选项和需求
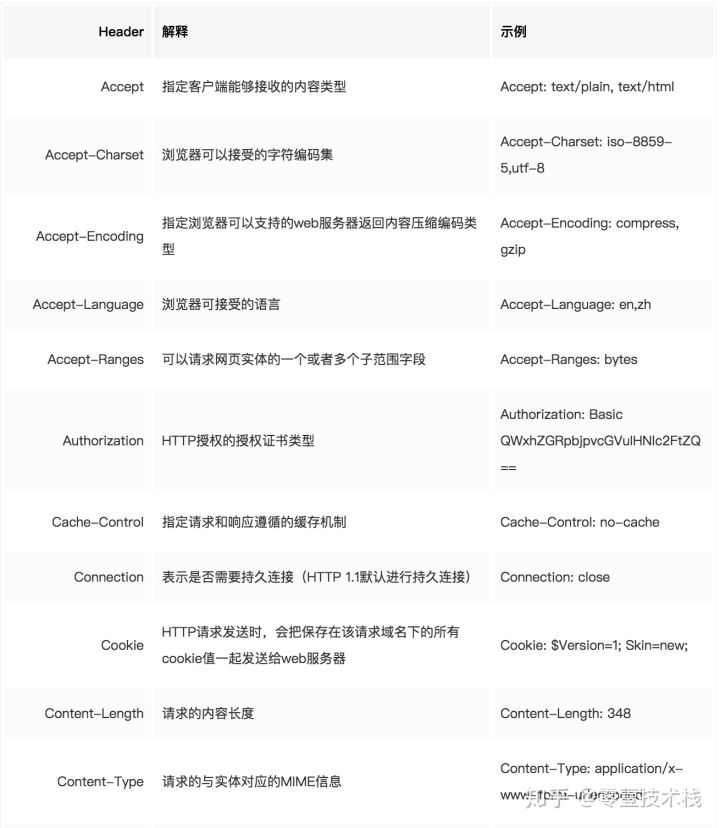
HTTP 请求头
消息报头由一系列的键值对组成,允许客户端向服务器端发送一些附加信息或者客户端自身的信息,主要包括:
HTTP请求正文
只有在发送POST请求时才会有请求正文,GET方法并没有请求正文。
HTTP 响应
HTTP响应也由三部分组成,包括状态行,消息报头,响应正文。

HTTP响应状态行
状态行也由三部分组成,包括HTTP协议的版本,状态码,以及对状态码的文本描述。例如:
1 | HTTP/1.1 200 OK (CRLF) |
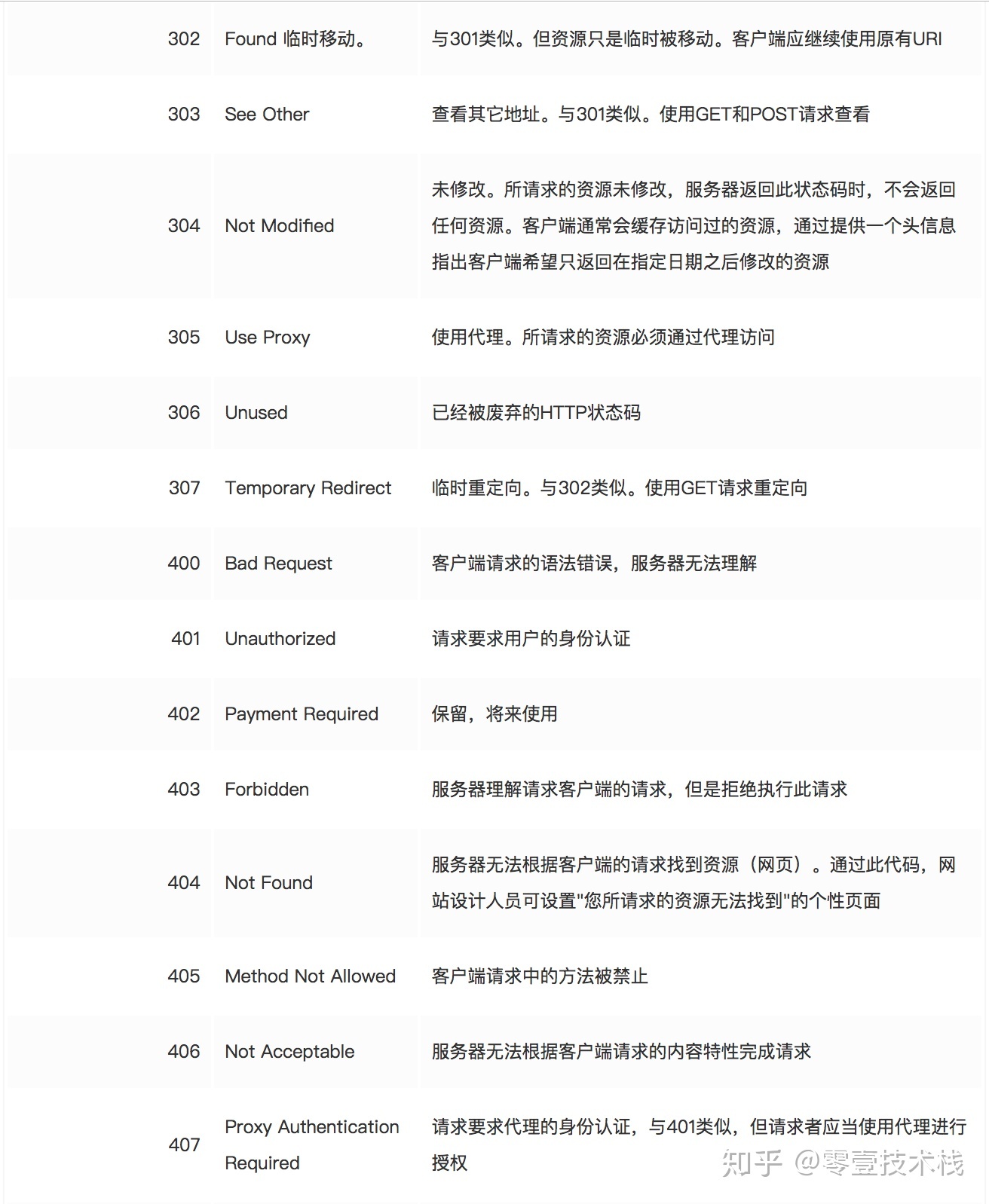
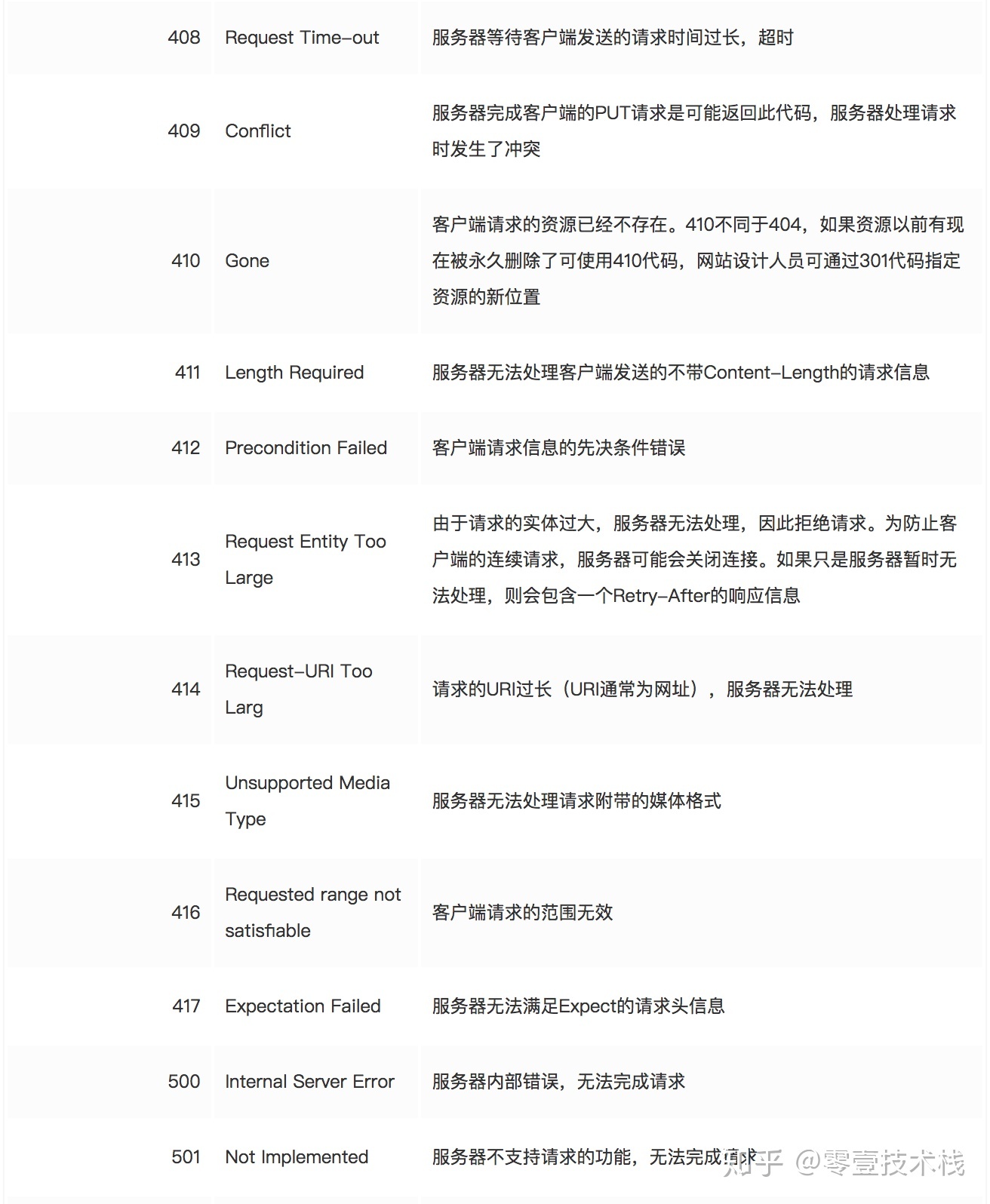
HTTP响应状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值: 1xx:指示信息 - 表示请求已接收,继续处理 2xx:成功 - 表示请求已被成功接收、理解、接受 3xx:重定向 - 要完成请求必须进行更进一步的操作 4xx:客户端错误 - 请求有语法错误或请求无法实现 * 5xx:服务器端错误 - 服务器未能实现合法的请求


reference
- 本文标题:HTTP协议
- 本文作者:9unk
- 创建时间:2019-11-04 16:35:02
- 本文链接:https://9unkk.github.io/2019/11/04/http-xie-yi/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!